Group
Group By
| Command | Syntax (MySQL/DB2) | Description | Example (MySQL/DB2) |
|---|---|---|---|
| GROUP BY | SELECT column_name(s) FROM table_name GROUP BY column_name(s) |
GROUP BY clause is used in collaboration with the SELECT statement to arrange data with identical values into groups. |
SELECT dep_id, COUNT(*) FROM employees GROUP BY dep_id;This returns the department IDs and the number of employees in them, grouped by the department IDs. |
Syntax:
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);- The
GROUP BYstatement groups rows that have the same values into summary rows, like “find the number of customers in each country”. - The
GROUP BYstatement is often used with aggregate functions (COUNT(),MAX(),MIN(),SUM(),AVG()) to group the result-set by one or more columns.
Customers:
| CustomerID | CustomerName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 1 |
Alfreds Futterkiste | Maria Anders | Obere Str. 57 | Berlin | 12209 | Germany |
| 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Avda. de la Constitución 2222 | México D.F. | 05021 | Mexico |
| 3 | Antonio Moreno Taquería | Antonio Moreno | Mataderos 2312 | México D.F. | 05023 | Mexico |
| 4 |
Around the Horn | Thomas Hardy | 120 Hanover Sq. | London | WA1 1DP | UK |
| 5 | Berglunds snabbköp | Christina Berglund | Berguvsvägen 8 | Luleå | S-958 22 | Sweden |
Orders:
| OrderID | CustomerID | EmployeeID | OrderDate | ShipperID |
|---|---|---|---|---|
| 10248 | 90 | 5 | 1996-07-04 | 3 |
| 10249 | 81 | 6 | 1996-07-05 | 1 |
| 10250 | 34 | 4 | 1996-07-08 | 2 |
Shippers:
| ShipperID | ShipperName |
|---|---|
| 1 | Speedy Express |
| 2 | United Package |
| 3 | Federal Shipping |
Example:
- List the number of customers in each country, sorted from high to low
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
ORDER BY COUNT(CustomerID) DESC;Output:
Number of Records: 21
| Count | Country |
|---|---|
| 13 | USA |
| 11 | France |
| 11 | Germany |
| 9 | Brazil |
| 7 | UK |
Group & Count
- Let’s say we want to select country from Author table
- And want them sorted in order
SELECT country
FROM Author
ORDER BY 1 # same as country = 1- Let’s say we want to count how many
DISTINCTcountries are in the Author table - We can use the
GROUP BYbecause it will create a group for everyUNIQUE/DISTINCTcountry in the table
SELECT country, COUNT(country)
FROM Author
GROUP BY country
# The way it is now it will output a column named country and the second column will be labeled 2 because it's the second col
SELECT country, COUNT(country) AS Count
FROM Author
GROUP BY country
# This output will give us a second column labeled CountGroup & Having
- We can further expand our query to limit the number of countries that ONLY have more than 4 titles
- In other words we want to extract the countries with a count >= 4
- We already covered
HAVINGso we use it here - HAVING is isolated to the
GROUP BYclause, soGROUP BYhas to be used right before it - While WHERE applies to the
SELECTclause
SELECT country, COUNT(country) AS Count
FROM Author
GROUP BY country
HAVING count(country >= 4)with JOIN
- List the number of orders sent by each shipper
SELECT Shippers.ShipperName, COUNT(Orders.OrderID) AS NumberOfOrders
FROM Orders
LEFT JOIN Shippers
ON Orders.ShipperID = Shippers.ShipperID
GROUP BY ShipperName;Output:
Number of Records: 3
| ShipperName | NumberOfOrders |
|---|---|
| Federal Shipping | 68 |
| Speedy Express | 54 |
| United Package | 74 |
Rollup
The ROLLUP is an extension of the GROUP BY clause. The ROLLUP option allows you to include extra rows that represent the subtotals, which are commonly referred to as super-aggregate rows, along with the grand total row. By using the ROLLUP option, you can use a single query to generate multiple grouping sets.
Note that a grouping set is a set of columns by which you group. For example, a query that returns the inventory by the warehouse, the grouping set is (warehouse).
SELECT warehouse,
SUM (quantity) qty
FROM inventory
GROUP BY warehouse;The following illustrates the basic syntax of the SQL ROLLUP.We will use the inventory table below:
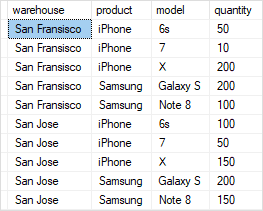
one column rollup
- The following statement uses the
GROUP BYclause and theSUM()function to find the total inventory by warehouse:
SELECT warehouse,
SUM(quantity)
FROM inventory
GROUP BY warehouse;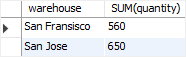
- To retrieve the total products in all warehouses, you add the
ROLLUPto theGROUP BYclause
SELECT warehouse,
SUM(quantity)
FROM inventory
GROUP BY ROLLUP (warehouse);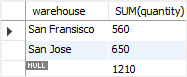
- As you can see in the result, the NULL value in the warehouse column specifies the grand total super-aggregate line. In this example, the ROLLUP option causes the query to produce another row that shows the total products in all warehouses
coalesce
We’ll cover coalesce in another part.
- To make the output more readable, you can use the
COALESCE()function to substitute the NULL value by theAll warehousesas follows:
SELECT
COALESCE(warehouse, 'All warehouses') AS warehouse,
SUM(quantity)
FROM inventory
GROUP BY ROLLUP (warehouse);
multiple columns rollup
- The following statement calculates the inventory by warehouse and product:
SELECT warehouse,
product,
SUM(quantity)
FROM inventory
GROUP BY warehouse,
product;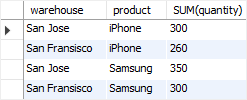
- Now we add the
ROLLUPclause
SELECT warehouse,
product,
SUM(quantity)
FROM inventory
GROUP BY ROLLUP (warehouse , product);
Note that the output consists of summary information at two levels of analysis, not just one:
Following each set of product rows for a specified warehouse, an extra summary row appears displaying the total inventory. In these rows, values in the
productcolumn set to NULL.Following all rows, an extra summary row appears showing the total inventory of all warehouses and products. In these rows, the values in the
warehouseandproductcolumns set to NULL.
partial rollup
You can use ROLLUP to perform a partial roll-up that reduces the number of subtotals calculated as shown in the following example:
SELECT warehouse,
product,
SUM(quantity)
FROM inventory
GROUP BY warehouse,
ROLLUP (product);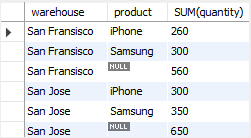
In this example, the ROLLUP only makes a supper-aggregate summary for the product column, not the warehouse column.
Coalesce
The COALESCE() function returns the first non-null value in a list.
Syntax: COALESCE(val1, val2, ...., val_n)
Technical Details
| Works in: | SQL Server (starting with 2008), Azure SQL Database, Azure SQL Data Warehouse, Parallel Data Warehouse |
|---|---|
- If we want to substitute a value from another column to use for the missing value in a different column, then we would use
COALESCE. - Let’s say we want to look at product name, but if that data is missing we want it to substitute product code for the product name, and we’ll put the new data in a new column
SELECT COALESCE(product,product_code) AS product_info
FROM MyTable- If you remember the example above: what we are asking is, if the value of warehouse is
NULLthen substitute it with ‘All warehouses’ - As you see in the image that’s what happened in the total row
SELECT COALESCE(warehouse, 'All warehouses') AS warehouse
- Here is another example
SELECT COALESCE(NULL, 'Pick Me', 'No Pick ME') AS answer
[OUTPUT] Pick Me