library(bigrquery) # R Interface to Google BigQuery API
library(dplyr) # Grammar for data manipulation
library(DBI)
projectid <- 'prime-depot-415622'
datasetid <- 'BikeShare'
con <- dbConnect((bigquery()),
project = projectid,
dataset = datasetid,
use_legacy_sql = FALSE)EDA
Rides per User
SELECT
subquery2.member_casual,
COUNT(*) AS trip_count
FROM
(
SELECT
subquery.member_casual,
EXTRACT(DAYOFWEEK FROM subquery.started_at) AS day_of_week,
EXTRACT(MONTH FROM subquery.started_at) AS month,
EXTRACT(YEAR FROM subquery.started_at) AS year,
EXTRACT(QUARTER FROM subquery.started_at) AS quarter,
EXTRACT(DATE FROM subquery.started_at) AS date,
TIMESTAMP_DIFF(subquery.ended_at, subquery.started_at, SECOND) AS ride_length
FROM
(
SELECT
CAST(ride_id AS STRING) AS ride_id,
started_at,
ended_at,
start_station_id,
start_station_name,
end_station_name,
end_station_id,
member_casual
FROM
trips19v1
UNION ALL
SELECT
ride_id,
started_at,
ended_at,
start_station_id,
start_station_name,
end_station_name,
end_station_id,
CASE
WHEN member_casual = 'member' THEN 'Subscriber'
WHEN member_casual = 'casual' THEN 'Customer'
ELSE member_casual
END
FROM trips20
) AS subquery
WHERE
(start_station_name <> "HQ QR" AND end_station_name <> "HQ QR")
AND
TIMESTAMP_DIFF(subquery.ended_at, subquery.started_at, SECOND) > 0
) AS subquery2
GROUP BY
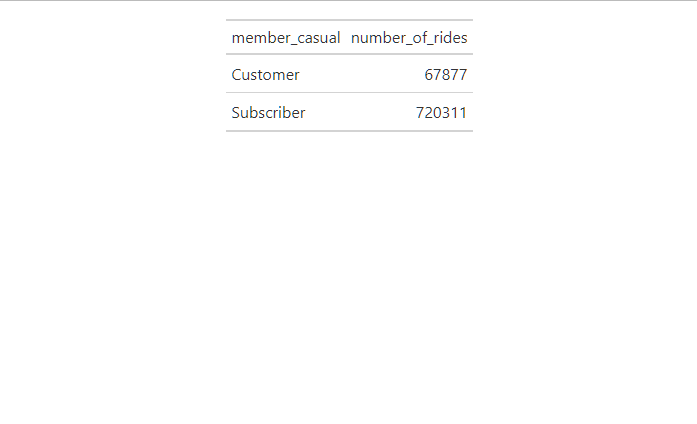
subquery2.member_casual;| member_casual | trip_count |
|---|---|
| Subscriber | 720311 |
| Customer | 67877 |
Group Rides
- Group the rides by user
- Separate by day of the week
NOTE: this chunk is the same as the one right above it, with the exception of the last few lines I marked, which were added to group the results
SELECT
subquery2.member_casual,
subquery2.day_of_week,
COUNT(*) AS trip_count
FROM
(
SELECT
subquery.member_casual,
EXTRACT(DAYOFWEEK FROM subquery.started_at) AS day_of_week,
EXTRACT(MONTH FROM subquery.started_at) AS month,
EXTRACT(YEAR FROM subquery.started_at) AS year,
EXTRACT(QUARTER FROM subquery.started_at) AS quarter,
EXTRACT(DATE FROM subquery.started_at) AS date,
TIMESTAMP_DIFF(subquery.ended_at, subquery.started_at, SECOND) AS ride_length
FROM
(
SELECT
CAST(ride_id AS STRING) AS ride_id,
started_at,
ended_at,
start_station_id,
start_station_name,
end_station_name,
end_station_id,
member_casual
FROM trips19v1
UNION ALL
SELECT
ride_id,
started_at,
ended_at,
start_station_id,
start_station_name,
end_station_name,
end_station_id,
CASE
WHEN member_casual = 'member' THEN 'Subscriber'
WHEN member_casual = 'casual' THEN 'Customer'
ELSE member_casual
END
FROM trips20
) AS subquery
WHERE
(start_station_name <> "HQ QR" AND end_station_name <> "HQ QR")
AND
TIMESTAMP_DIFF(subquery.ended_at, subquery.started_at, SECOND) > 0
) AS subquery2
GROUP BY
subquery2.member_casual,
# ----- The next few lines are the only lines that were added to the above chunk of code
subquery2.day_of_week
ORDER BY
subquery2.day_of_week,
subquery2.member_casual;| member_casual | day_of_week | trip_count |
|---|---|---|
| Customer | 1 | 18652 |
| Subscriber | 1 | 60196 |
| Customer | 2 | 5591 |
| Subscriber | 2 | 110430 |
| Customer | 3 | 7311 |
| Subscriber | 3 | 127974 |
| Customer | 4 | 7690 |
| Subscriber | 4 | 121902 |
| Customer | 5 | 7147 |
| Subscriber | 5 | 125228 |
Breakdown by Quarter
SELECT
subquery2.quarter,
subquery2.member_casual,
subquery2.day_of_week,
COUNT(*) AS trip_count
FROM
(
SELECT
subquery.member_casual,
EXTRACT(DAYOFWEEK FROM subquery.started_at) AS day_of_week,
EXTRACT(MONTH FROM subquery.started_at) AS month,
EXTRACT(YEAR FROM subquery.started_at) AS year,
EXTRACT(QUARTER FROM subquery.started_at) AS quarter,
EXTRACT(DATE FROM subquery.started_at) AS date,
TIMESTAMP_DIFF(subquery.ended_at, subquery.started_at, SECOND) AS ride_length
FROM
(
SELECT
CAST(ride_id AS STRING) AS ride_id,
started_at,
ended_at,
start_station_id,
start_station_name,
end_station_name,
end_station_id,
member_casual
FROM trips19v1
UNION ALL
SELECT
ride_id,
started_at,
ended_at,
start_station_id,
start_station_name,
end_station_name,
end_station_id,
CASE
WHEN member_casual = 'member' THEN 'Subscriber'
WHEN member_casual = 'casual' THEN 'Customer'
ELSE member_casual
END
FROM trips20
) AS subquery
WHERE
(start_station_name <> "HQ QR" AND end_station_name <> "HQ QR")
AND
TIMESTAMP_DIFF(subquery.ended_at, subquery.started_at, SECOND) > 0
) AS subquery2
GROUP BY
subquery2.quarter,
subquery2.member_casual,
subquery2.day_of_week
ORDER BY
subquery2.quarter,
subquery2.day_of_week,
subquery2.member_casual;| quarter | member_casual | day_of_week | trip_count |
|---|---|---|---|
| 1 | Customer | 1 | 18652 |
| 1 | Subscriber | 1 | 60196 |
| 1 | Customer | 2 | 5591 |
| 1 | Subscriber | 2 | 110430 |
| 1 | Customer | 3 | 7311 |
| 1 | Subscriber | 3 | 127974 |
| 1 | Customer | 4 | 7690 |
| 1 | Subscriber | 4 | 121902 |
| 1 | Customer | 5 | 7147 |
| 1 | Subscriber | 5 | 125228 |
Same Station Rides
# ________ We can use the code above and substitute the
WHERE
subquery2.start_station_id = subquery2.start_station_id
OUTPUT
23626Observations
- If we group trip_count and sort it in order, a glaring figure jumps out at us:
- the top 3 stations in rides (by 50% more than the fourth place are in this order: Station # 192, 91, 77
| 1 | Subscriber | 192 | 13799 |
| 2 | Subscriber | 91 | 13434 |
| 3 | Subscriber | 77 | 12891 |
| 4 | Subscriber | 133 | 8720 |
- If we add the other usertype to the data and recalculate we get:
| 1 | 192 | 14155 |
| 2 | 91 | 1640 |
| 3 | 77 | 13362 |
- As you see the Customer users account for:
- 356 at station 192 out of the total of 14155 trips
- 206 at station 91 out of the total of 13640 trips
- 471 at station 133 out of the total of 13362
TABLEAU
Total Rides per Day
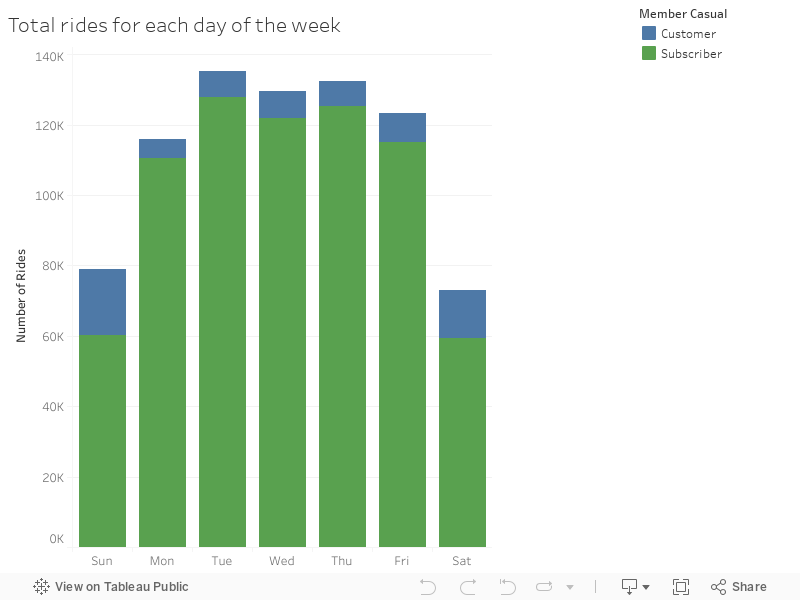
Rides per Day/Year
- Let’s see what has happened from year to year for the same quarter Q1.
- It appears that the number of rides have gone up for all days EXCEPT Thursday and Fridays, where we see the number of rides have decreased

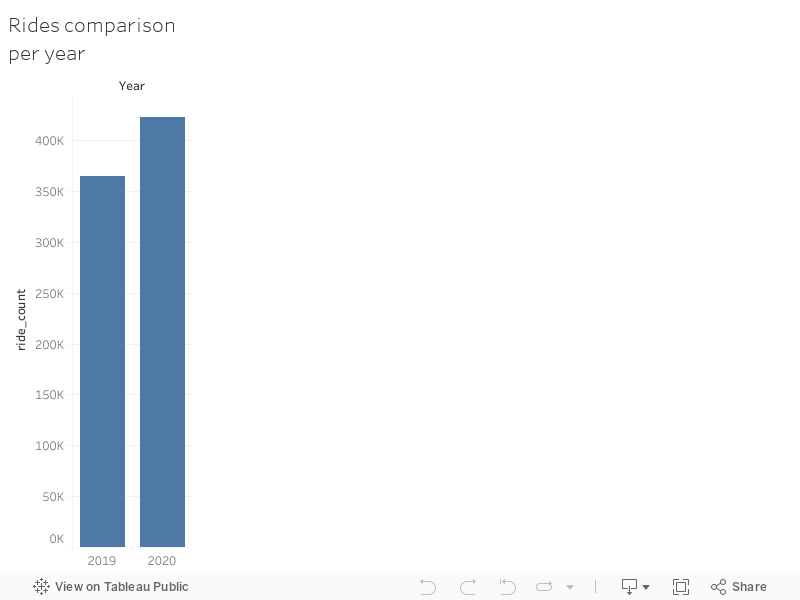
Rides per Year
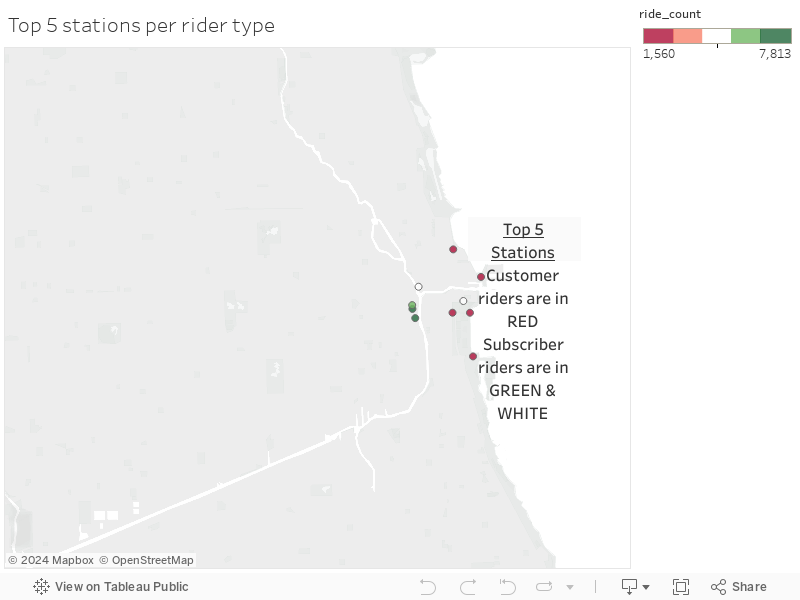
Location of Top 5
- Let’s see if the busiest 5 stations are located near a landmark that can help us improve our service
Top 5 Starting Stations
- Let’s identify the top 5 performing starting stations
- Maybe the locations can help us understand our users
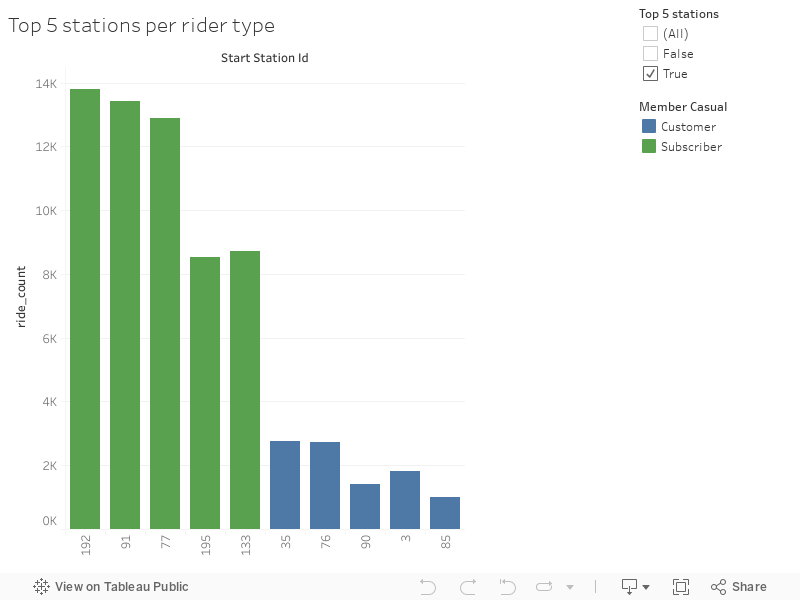
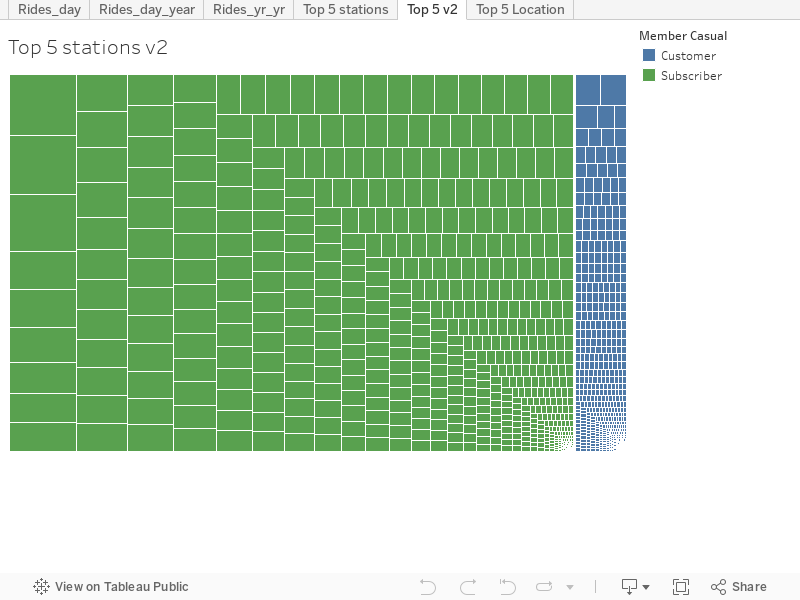
Interactive Top 5 Graphs
- I’ve gathered multiple top 5 charts together to help me speed up the understanding of the usage
- Just click on the tabs to change views
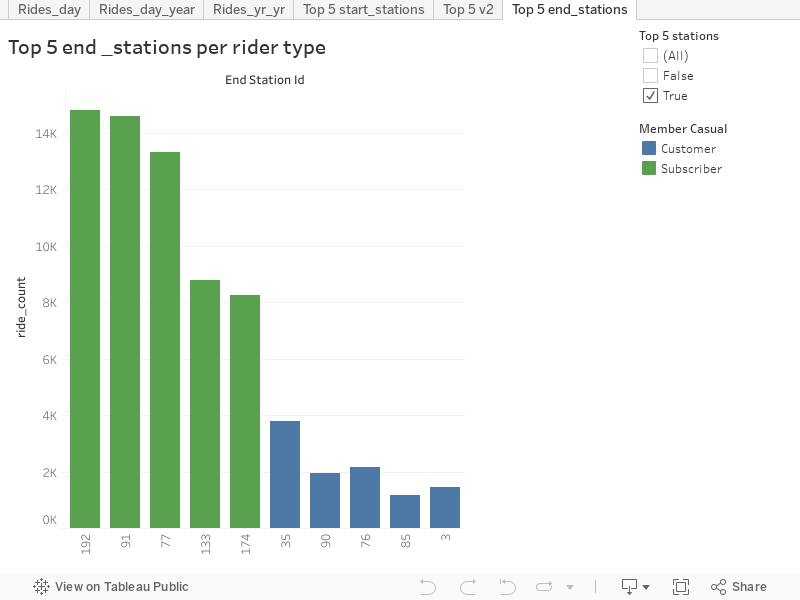
Top 5 Ending Stations
- I had identified the top 5 starting stations how about we look at the top 5 ending stations
- Maybe this will help us direct our bike availablity or
- Maybe we can better understand our user usage
- Once again I gathered multiple charts together for easier exploration
Top 5 Start=End
- Let’s see if there is a pattern between starting and ending stations
- Let’s look how often our user return the bikes to the start station

Observations
- The company claims that “Cyclistic users are more likely to ride for leisure, but about 30% use the bikes to commute to work each day”, how is that numbered calculated?
- The two plans offered to casual riders: single-ride passes and full-day passes are not tracked in the data provided, all we have is user type: “Customer” or “Subscriber”
- The data provided doesn’t link any of the rides to an actual account. Why don’t we track by userId? Don’t Subscribers have to create an account? Why are we just sorting the data by “Member Casual”.
- We can gather more insight if the rideId is linked to a userId, is the data available but not provided for analysis?
- How are docking station locations related to subway, train, or bus stations?
- Are docking stations near parking structures or major tourist, business centers?
- Are users coming to the city via other mode of transportation and using bikes within the city for commuting?
- The objective of the project is to find ways to convert “Customers” to “Subscribers” which is logical except the data provided doesn’t support the theory proposed by Mrs. Moreno. The data shows a large discrepancy between the two users, as Customers account to 9% of Subscribers usage. See table below.
- The data does not show how many actual users are represented by each type. It is illogical to use rideId as userId. The data provided does not promote an insightful analysis regarding the particular hypothesis presented.
- The idea that converting 9% of rides will improve the bottom line, sure but at what cost? How many users are we converting? How many Subscribers do we already have?
- Considering the fact that I am not provided with data relevant to the proposed hypothesis, I would shift my focus on other issues that the data has exposed.
- The facts that weekday ride numbers have been on the decrease for the busiest stations is alarming (see the last table below). The top stations are very close in proximity to one another, so it is possible that users are not getting good service or possibly a competitor has entered the arena and is targeting that specific small area where the top stations are located. Maybe inventory at those stations doesn’t support the volume of rides initiated from there?
- The fact that inventory at those stations is not tracked needs to be addressed.
- The top stations are far more important to the bottom line than wasting resources on the hypothesis that has been proposed, with the data provided. We cannot worry about converting 9% of rides while the top 3 stations are losing rides at a higher pace and by larger numbers than 9%.
Recommendations
- Modify the data we track.
- Implement userId so we can focus our analysis and be more insightful.
- Focus on UX at the top stations.
- Stabilize ride numbers at the top stations.
- Reassess the situation in the near future after modifications have been implemented.